
Apache Spark and the Big Data Ecosystem

Apache Spark and the Big Data Ecosystem
Ever wondered how companies like Uber and Netflix process massive amounts of data in near real-time?
In this article, we’ll lay the groundwork for our Apache Spark journey. You’ll learn how Spark fits into the broader Big Data ecosystem, explore core architectural components and discover how these components simplify Big Data processing. By the end of this article, you’ll confidently understand Spark’s architecture and be able to apply these concepts effectively to your own Big Data projects.
Quick Refresher: Big Data
Before we go down the rabbit hole, let’s take a step back and view the broader picture. What does Big Data mean to you? Every enthusiast loves the 5 V’s of Big Data¹ — do you?
- Volume. The most obvious one — the massive amount of data. Like big Numbers? Think in petabytes of customer interactions, transaction logs or IIoT data
- Velocity. The incredible speed at which data is created, processed, stored and analyzed
- Variety, Veracity and last but not least Value
But are you familiar with the essential properties of a Big Data system? Let’s summarize these properties²:
- Robustness and Fault Tolerance, Scalability, Low latency Reads and Writes, Ad hoc queries and Debuggability
Apache Spark comes into Play
Now that we’ve refreshed our understanding of Big Data characteristics, let’s see how Apache Spark steps into the picture and addresses these challenges. We’ll first explore Spark’s general architecture, understand how it simplifies Big Data tasks, and gain clarity on how the different components of its distributed architecture interact seamlessly.
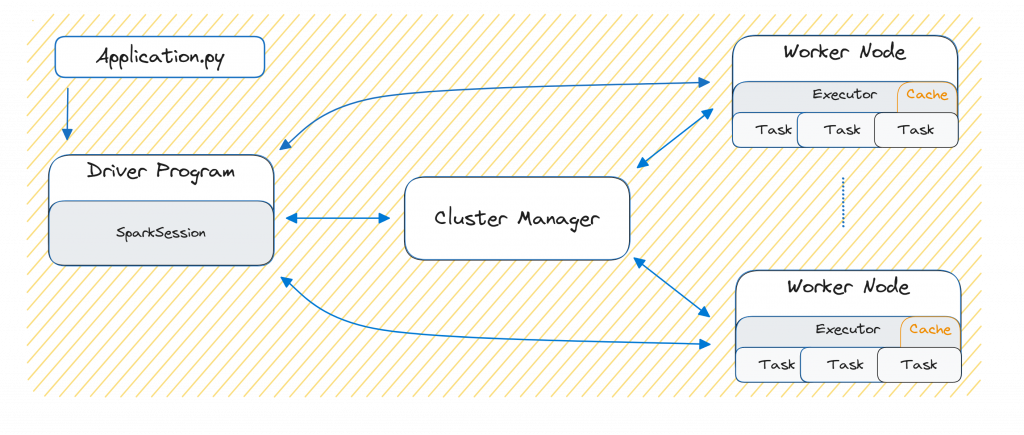
At a high level view, we have three primary components. The Driver Program that orchestrates and controls data processing tasks, the Cluster Manager which manages the resources of the cluster efficiently and the Worker Node which executes the processing tasks assigned by the Driver Program.
So far so good. How do we actually launch our Big Data processing jobs? To run your Spark application — such as Application.py on a cluster, Spark provides a simple straightforward script: spark-submit.sh . This script launches the Driver Program, typically starting it within the same process that submits your Application.py¹¹.
./bin/spark-submit --master spark://127.0.0.1:7077 /python/Application.py</code>The Driver Program: The Brain of the Cluster
The Driver Program acts as the brain of the cluster. It’s responsible for managing and coordinating the execution of your Application.py. It submits jobs, calculates execution plans, schedules tasks, gathers results and presents these to the user.
When writing a Spark Application, you’ll typically define a SparkSession object in your Application.py to define high-level Spark logic on top of it. Moreover, the Driver Program uses the SparkSession to communicate efficiently with the entire cluster.
The first essential step performed by the Driver Program is to determine resources. It achieves this by communicating with the Cluster Manager. This occurs after the following code expression will execute (or implicitly during the spark-submit.sh).
spark = (
SparkSession.builder
.appName("Application")
.getOrCreate()
)The Cluster Manager: Allocating Resources Efficiently
The Cluster Manager is responsible for managing cluster resources. It maintains awareness of multiple Worker Nodes, allocates resources and launches executor processes on available Worker Nodes¹². Another essential role is to monitor the health of the Worker Nodes, detects failures or restarts failed tasks, ensuring robust and fault-tolerant operation.
The Worker Node: Compute Powerhouse
The Worker Nodes provide the computational power in a Spark cluster. Each Worker Node hosts one or more Executor processes, each running in its own Java Virtual Machine (JVM). When you submit an Application.py the Cluster Manager launches Executors with predefined resource allocations dedicated specifically to your application.
The Executor is responsible for executing assigned Task(s) in parallel and manage data storage both in-memory or on disk. Executors receive instructions directly from the Driver Program via the SparkSession through a serialization and deserialization processes. They also continuously report task progress, send back computed results, and request new tasks from the driver.
When we complete the circle we should step into our Application.py, take a look at our instructions and can derive some Jobs or simple high level Spark method calls. Spark internally breaks down the Jobs into smaller units called Tasks. But what exactly are these Jobs, and how do we feed data into it?
Diving Deeper into Spark’s Job Anatomy
Imagine we have a very simple Application.py that generates some user data (e.g. name, age and gender). Our Spark Cluster is already up and running, the Executors are awaiting tasks. The Driver Program has already established a connection through a SparkSession object (in our case the variable spark).
Let’s feed Spark with some data. First we need a basic but fundamental Spark data container called Resilient Distributed Dataset, short RDD¹³. A RDD is a collection of Partitions that may (but don’t have to) be computed on different nodes in a distributed system³.
A large dataset is stored as RDD across multiple partitions, often spread over several Executors.
These partitions are immutable and preferably stored in-memory within Executor(s) on different Worker Nodes(s). This guarantees very fast access for computation.
Let’s create our dataset in Spark:
data = Seq(
("Alice", 34, "F"), ("Bob", 45, "M"), ("Cathy", 29, "F"),
("Eva", 22, "F"), ("Frank", 33, "M"), ("Grace", 28, "F"),
("Ian", 31, "M"), ("Jack", 50, "M"), ("Karen", 27, "F"))
# sample data
data = [("Alice", 34, "F"), ("Bob", 45, "M"), ("Cathy", 29, "F"),
("Eva", 22, "F"), ("Frank", 33, "M"), ("Grace", 28, "F"),
("Ian", 31, "M"), ("Jack", 50, "M"), ("Karen", 27, "F")]
# create data with the sparksession object
rdd = spark.sparkContext.parallelize(c=data, numSlices=3)
# lets show us the result as a table
rdd.collect()+-----+---+------+
| Name|Age|Gender|
+-----+---+------+
|Alice| 34| F|
| Bob| 45| M|
|Cathy| 29| F|
| Eva| 22| F|
|Frank| 33| M|
|Grace| 28| F|
| Ian| 31| M|
| Jack| 50| M|
|Karen| 27| F|
+-----+---+------+There we go. We’ve successfully collected from Spark’s RDD. While this seems straightforward, let’s take a look behind the scene.
Behind the Scenes: Parallelism and Partitions
When we executed collect(), Spark serialized our instructions and sent them to Executor. The executors processed these instructions in parallel using partitions. Let’s inspect our partitions explicitly:
# lets look behind the scene, show us the partitions
rdd.foreachPartition(lambda x: print("Partition",list(x)))
Partition [('Alice', 34, 'F'), ('Bob', 45, 'M'), ('Cathy', 29, 'F')]
Partition [('Eva', 22, 'F'), ('Frank', 33, 'M'), ('Grace', 28, 'F')]
Partition [('Ian', 31, 'M'), ('Jack', 50, 'M'), ('Karen', 27, 'F')]Everything works as expected. Spark splits the RDD into a set of three Partitions. Each partition can now be processed independently, enabling parallel computation and representing Spark’s smallest execution unit — a Task. Let’s put them together and do operations in parallel. The Work is to load and filter data. Sparks defines Tasks, one for each Partition.
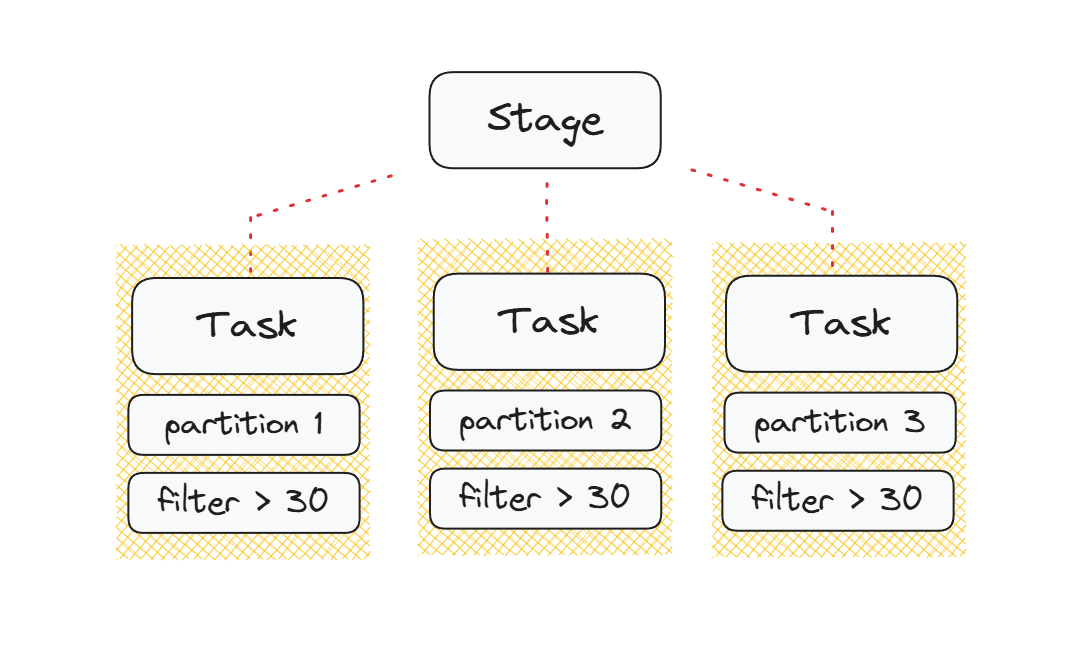
How Spark Expressions are really Evaluated
Sadly the things are a bit more complicated as we would suggest. Let’s imagine we want to filter people who are older than 30 years, group by gender and count the results.
# narrow transformation
filtered = rdd.filter { case (_, age, _) => age > 30 }
# wide transformation
grouped = filtered.groupBy { case (_, _, gender) => gender }
# action
result = grouped.collect()
result.foreach {
case (key, values) => println(s"$key: ${values.size}")
}
M: 4
F: 1Again, the Driver Program analyzes our code¹⁴ but doesn’t execute until it reaches an Action, in this case, collect(). Spark employs lazy evaluation, meaning it doesn’t immediately compute transformations until an action is triggered. At that point, the Driver Program calculates an execution plan with its DAGScheduler. Let’s take a break and step into such a plan.
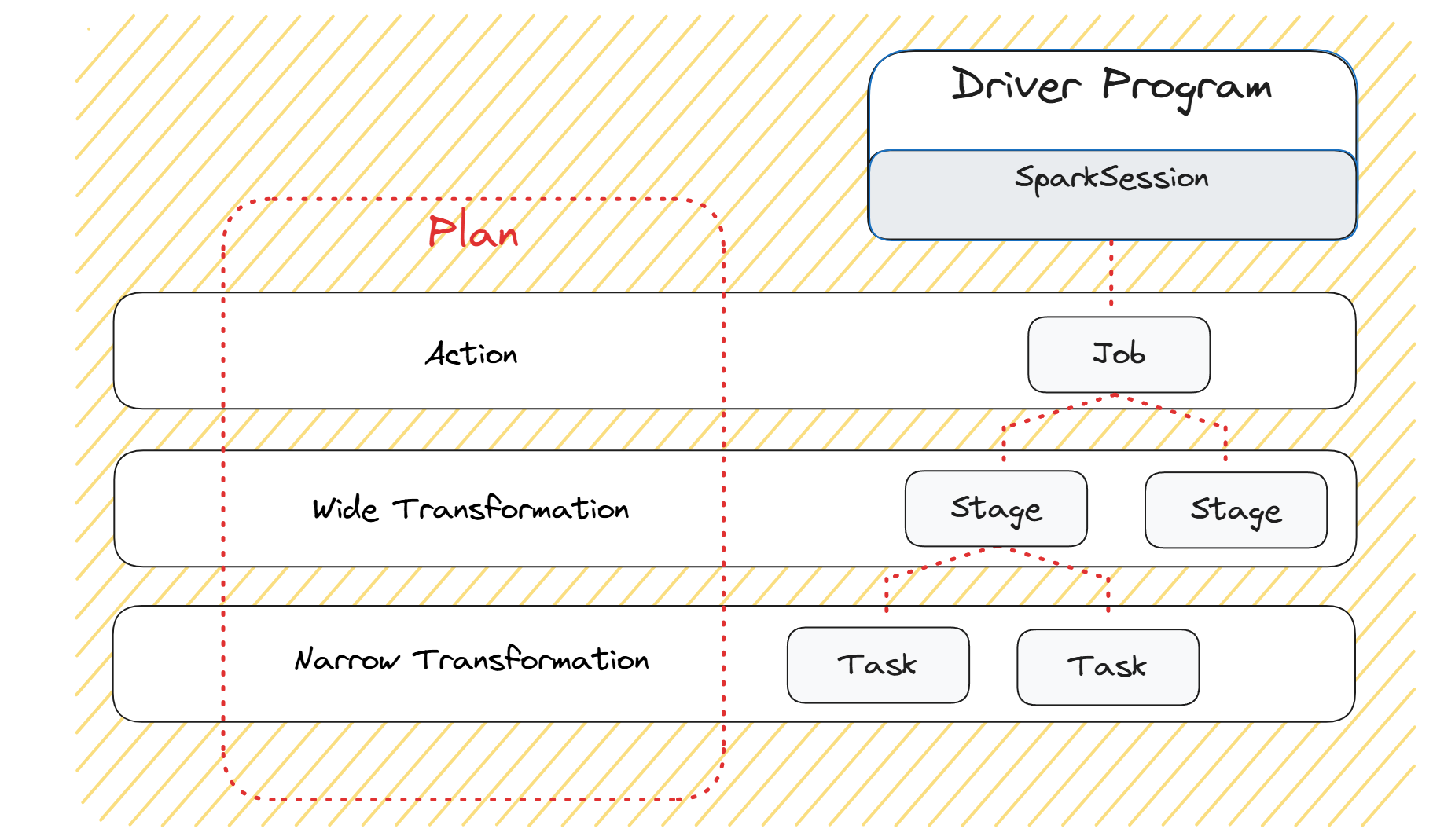
The DAGScheduler breaks down the operations in a way that we can distinguish between:
- Action as Jobs: The highest element in the execution hierarchy. In our Example the
collect()function. A general rule of thumb is that Actions return something that is not an RDD¹⁵ - Wide Transformations as Stages: The wide transformations define the breakdown of jobs into stages like the
groupBy()function. To perform the work more efficiently, we can just further process groups independent from each other. Wide transformations typically trigger shuffles, requiring data redistribution across Worker Nodes and may request data writing via BlockManager. - Narrow Transformation as Tasks: The smallest unit which represents one local computation like
filter(). Narrow transformations, trigger pipelining, meaning that multiple narrow transformations are performed in-memory. The Tasks will be scheduled on our Worker Nodes inside the assigned Executor via TaskScheduler.
Nice! We have a User Interface
The way Sparks show its work is a built-in web User Interface launched by the Driver Program (on Port 4040). It visualizes Spark operations, including:
Stages: showing details of individual execution stages and task distribution


The Jobs: Triggered by our collect() method. Spark gives us information about how many Stages and Tasks were involved and how long the process was.
The Stages: Showing how many Stages were needed by Spark to solve the Job. We can identify, that we also have an amount of Task per Stage. Not really magical, that the count matches exactly three, like our specification above in code numslices=3. With three partitions, each stage processes exactly three tasks concurrently.
Wonderful Directed Acyclic Graph (DAG)
Spark’s DAGScheduler generates a DAG that clearly visualizes dependencies and stages. For our example, the DAG looks like the
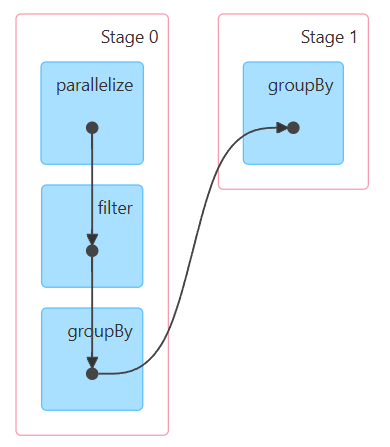
Stage 0: This stage appears straightforward. In our first step, we parallelize our local data, distributing it across available executors. Each executor then filters the data according to our specified condition: case (_, age, _) => age > 30. Since we previously defined that the operation occurs at the partition level, each executor independently groups its partitioned data by the key case (_, _, gender) => gender.
Stage 1: Each executor has completed its work on a partition. However, we want to aggregate the results from all partitions. The driver program gathers results from each executor and finalizes the groupBy() operation. The final result can now be printed as: M:4 and F:1. Keep in mind that this step triggers a shuffle operation, causing network traffic.
Recap the Driver Program
Now, we have a better understanding how Spark uses its architecture to solve and calculate user code in a parallel manner.
The last sentences summarize the important components of the Driver Program (for every spark interview very important):
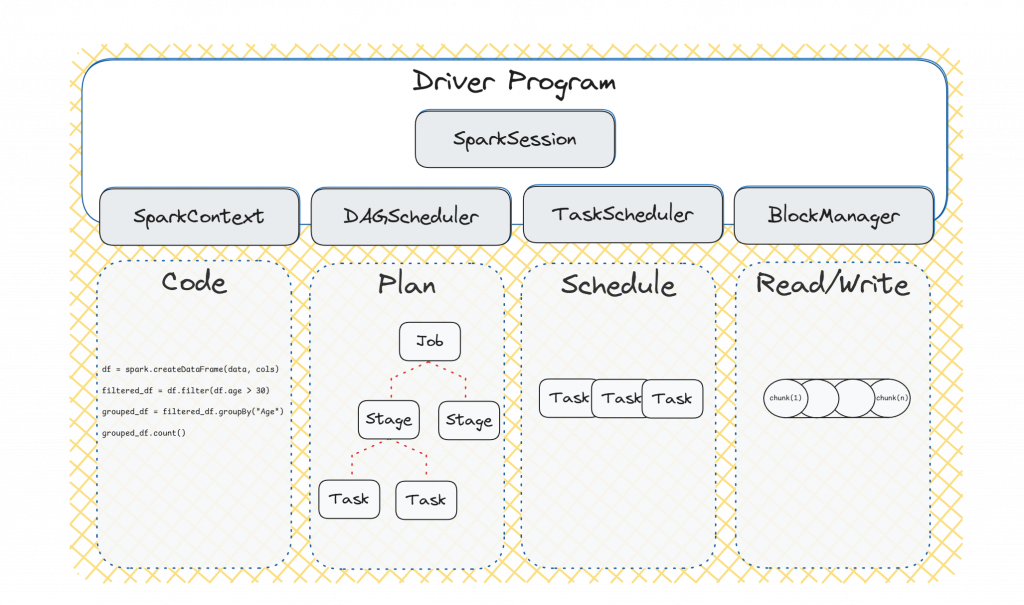
The SparkContext interprets several instructions within the code. After that the DAGScheduler calculates an execution plan. The TaskScheduler schedules Tasks onto available Executors. The BlockManager manages data storage, caching and retrieval between Executor and Driver Program.
This describes the general architecture of Spark. By the nature of distributed systems, Spark offers us to run it on several infrastructures like Single Host, Distributed Hosts and of course Kubernetes. If you’re interested in a single host (or Standalone) and Kubernetes deployment, I will provide you the solution and a ready to go GitLab repo in my other articles.
Combine the Big Data Properties with Spark
In our Introduction we recapped properties for a Big Data System. So let’s evaluate if Spark matches those Properties from an architectural perspective¹⁶
Fault Tolerance. The scope is the Executor on the Worker Node. If an Executor fails, the Driver Program simply requests another Executor from the Cluster Manager.
Scalability. If the workload goes bigger and bigger we can simply add more Worker Nodes. The Cluster Manager registers them, sharing available resources among Spark applications.
What’s Next?
By understanding Spark’s architecture and execution details, you’re now equipped to deploy Spark on various infrastructures (single-node, distributed, or Kubernetes). Interested in deploying Spark standalone or on Kubernetes? Look for my upcoming articles, where I provide step-by-step deployment guides and a ready-to-use GitLab Repository
About Me and Final Words
Thank you for following along! If you’d like to learn more about me, check out my bio or visit my website at runrabbit.dev.
Feel free to reach out or ask questions about software engineering, Big Data (especially Apache Spark and Apache Kafka), Kubernetes, or cloud processing with Azure. I’m here to help you on your journey into modern data solutions!
[1] Hiba, Jasim; Hadi, Hiba; Hameed Shnain, Ammar; Hadishaheed, Sarah; Haji, Azizahbt. (2015). Big Data and Five V's Characteristics. International Journal of Advances in Electronics and Computer Science. ISSN: 2393-2835.
[2] Marz, Nathan; Warren, James. (2015). Big Data: Principles and Best Practices of Scalable Realtime Data Systems. Manning Publications.
[3] Karau, Holden; Warren, Rachel. (2017). High Performance Spark. O'Reilly Media.
Annotation
[11] It depends on the cluster mode | Using: Standalone
[12] It depends on deploy mode | Using: Cluster
[13] There are also other ones | Using: RDD cause of learning purpose
[13] Switchting from Python to Scala language | Cause: Better DAGVis
[16] Means that we don't look at data modeling techniques here